PhD Thesis: Capturing Distributions over Worlds for Robotics with Spatial Scene Grammars
Capturing distributions over environments to help robots and their designers understand the challenges they'll face.
github.com/gizatt/spatial_scene_grammars [WIP!]
Over the course of my PhD, I used simulation for many things, like testing Atlas’ walking behaviors during the DRC; prototyping perception and control systems for the MIT Hyperloop vehicle before its test flight; or putting robot arm code used by my lab under CI. But simulation can be so much more than that – in my PhD, I wrangled with some fundamental questions about how we can better align simulation to reality in a high-level way – how we can capture the distribution of real worlds our robots will face, and reproduce that distribution in sim.
My PhD project focused on figuring out the tooling to capture a probability distribution $p(world)$ of real-world environments. Capturing a distribution over worlds is, at its core, a hard problem because it involves capturing a distribution over a mixed discrete and continuous distribution: specifically, how many objects of a given type are in a scene, and where those objects are, covary with each other in complex ways. If we could capture this distribution, we could:
-
Sample from $p(world)$ to generate tons of diverse, realistic, interesting environments to thoroughly test our perception and control algorithms in simulation (or for making game environments, or for quickly generating realistic backdrops in movies, etc…).
-
Use $p(world)$ to do inference. This can take the form of outlier detection; reasoning about likely underlying or hidden structure in an observed world; or model parameter estimation to align our modeled distribution to reality.
Spatial Scene Grammars

The above problem is almost absurdly broad; I’m exploring one of many possible avenues for tackling this problem. Specifically, I’m looking at using scene grammars as a representation for this distribution over worlds.
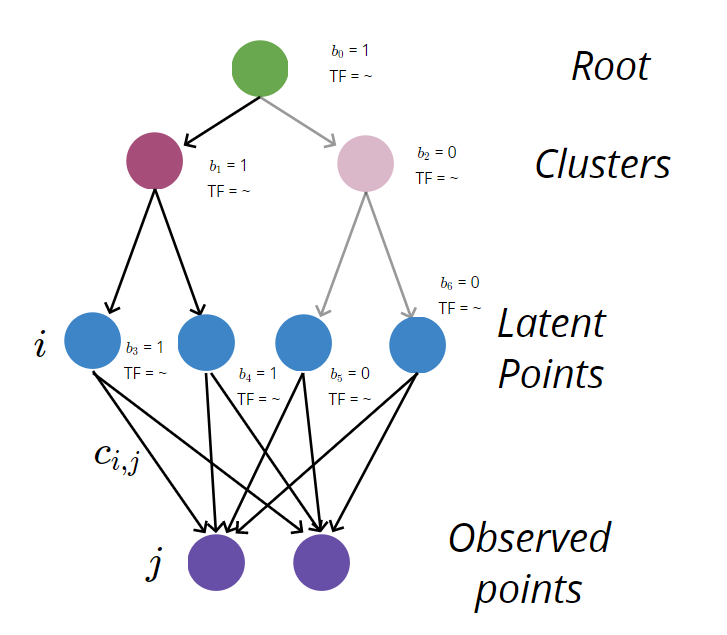
In the course of my thesis, I develop a custom class of spatial scene grammars to describe the spatial distribution of varying numbers of objects from a set of known classes. Scene grammars are a form of procedural model that suppose that objects belong to a single “parent” object – where the parent could be another actual object (like a cup on a table), or some abstract grouping of objects (like a plate belonging to a stack of plates). This grammar dictates probabilistic relationships between parents and children: how many cups tend to appear on tables, and where on that table those cups tend to appear. A draw from a scene grammar is a scene tree, which describes that set of hierarchical relationships in the scene.
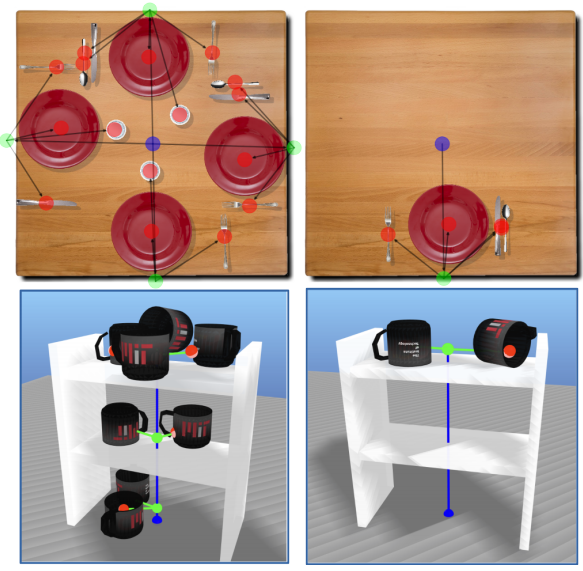
While scene grammars are (intentionally) limited in the scene structures they can describe, they’re remarkably flexible! My work at ICRA 2020 (paper, talk) showed that I can parameterize these grammars and align those parameters to an observed dataset of scenes to do “distribution matching” – i.e., make my grammar produce scenes that look, as much as possible, like real scenes. This thesis refines those ideas into a complete tool set: a carefully constructed grammar formulation, which is co-designed with novel mixed-integer-programming scene parsing techniques; an approximate expectation-maximization parameter inference strategy; and tools for sampling scenes from a grammar under structure and pose constraints.
Contributions and active problems
There’s tons of problems hidden here, the sum of which constitute my PhD.
- Data generation. Where do we get data to feed this system? One tactic I’m using is collecting fully labeled scene data using a custom-built motion control setup that lets me force my labmates to assemble “realistic” scenes for me.
- Scene parsing. Scene parsing – that is, figuring out the whole scene tree and relationships that produced it, given a grammar – can be really hard if the grammar includes lots of “hidden structure”, like object groups. At its biggest scale, this is a hard and general inverse procedural modeling problem. But parsing is too useful to give up on: it enables both outlier detection and parameter inference. Can I apply my background in mixed integer optimization to tackle the hard combinatorial choices at the hard of scene parsing?

-
Sampling under constraints. Scene grammars are great at capturing hierarchical or pairwise relationships between objects, but some critical constraints on environments don’t follow that pattern: for example, nonpenetration between all objects. Can I support sampling from a scene grammar, conditioned on satisfaction of some additional set of constraints?
-
Fitting grammars to image data. In my existing work, I model observed worlds as collections of objects – and to align my model to a dataset, I assume each entry in the dataset is a collection of fully observed objects. But what we really have access to is just images. Can I align my scene grammars to collections of image data? I’m exploring whether I can do this in a self-supervised way (using training data from the procedural model itself), using dense descriptors or keypoints as an intermediate representation.